Text Recognition (OCR)
Extract existing burned-in subtitles from video frames
What Is Text Recognition (OCR)
The Text Recognition (OCR) feature extracts existing burned-in subtitles from video frames and generates an editable SRT subtitle file. It is ideal for videos that already have visible subtitles but no separate subtitle file, such as downloaded videos with hardcoded subtitles, TV show recordings, etc.
Unlike speech recognition, OCR analyzes the video image rather than the audio track, so it can recognize any text that has been "burned in" to the video frames.
How to Use
- Import videos into the media libraryDrag video files into the GeekLink media library, or click the "Add Videos" button to select files.
- Pick "Already on screen"Choose this option in the settings panel (it reads the subtitles off the picture — i.e. OCR), for video where the subtitles are baked into the image.
- Choose the source languageSelect the OCR recognition language for the video subtitles.
- Click "Run Text Recognition"After confirming your settings, click the button to start processing.
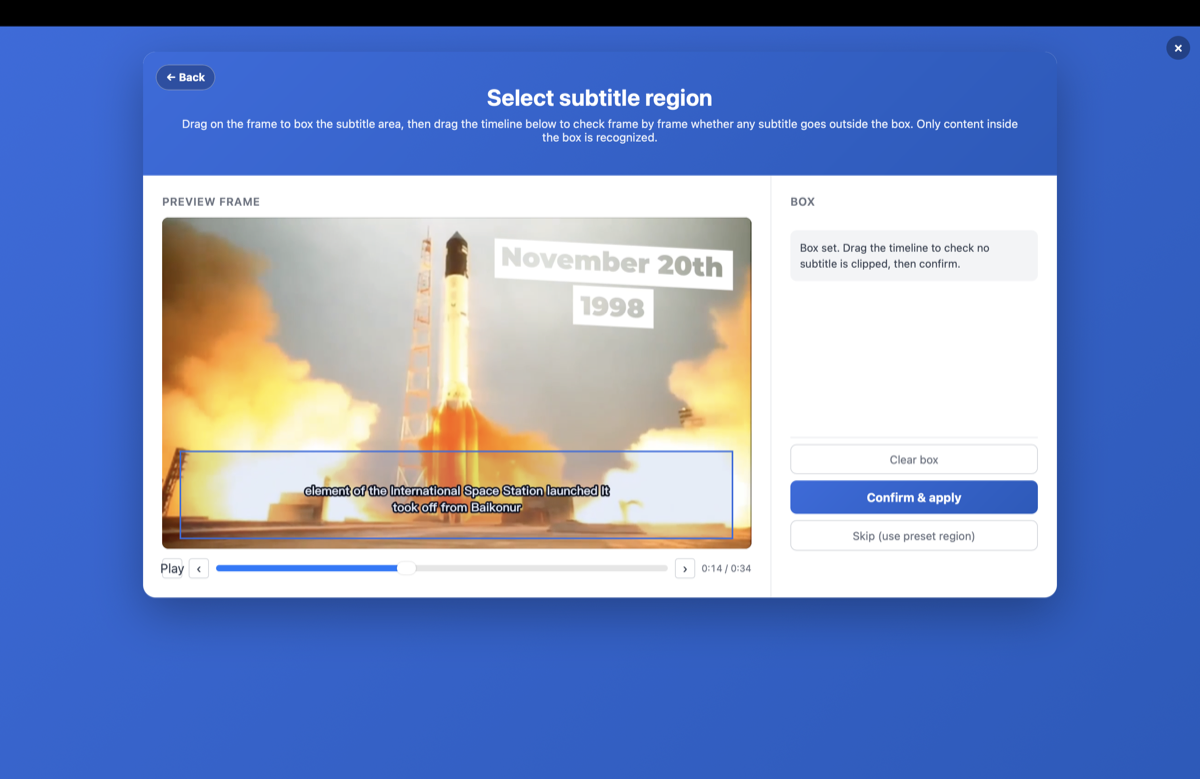
- Confirm the subtitle areaWhen the picker opens, the subtitle line is detected automatically and marked in red at its exact position — in most cases just scrub the timeline to verify the mark stays on the subtitles and hit Confirm. If the detection is off, drag on the frame to draw a box instead. OCR reads only the text inside that area and automatically ignores logos, watermarks, and channel badges (see details below).
- Color sampling (optional)Only if you turned on "Fine-tune subtitle filtering by color" in More settings: you enter the color picker step -- paint over the subtitle text on a video frame to sample its color (see details below). Otherwise OCR reads every line in the box and this step is skipped.
- Confirm colorAfter painting in the color picker, click "Confirm Color" to continue.
- Wait for OCR to finishThe system automatically scans video frames to extract text content.
- View resultsDone! Open the subtitle editor to view and edit the recognition results.
Confirm the Subtitle Area
After you click Run, the region picker opens and detects the subtitle line automatically: the exact position is marked in red, and a "Detected subtitle line" item appears on the right. In most cases you just scrub the timeline, verify the red mark stays on the subtitles, and hit Confirm — no manual box needed.
If the detected position is off, drag on the frame to draw a box — your box takes precedence (the detected line stays listed on the right and can be removed individually with its Delete button). This step tells OCR to read only the text inside that area and ignore on-screen logos, watermarks, and channel badges, so the extracted result contains just the subtitle lines.
The region picker now highlights detected text areas live: pause or scrub the timeline and boxes appear around every piece of text OCR will pick up, so you can see at a glance whether your box is accurate and whether stray text is sneaking in (tick "Hide detected text boxes" to turn the overlay off). If small interfering text ends up inside your box — game UI numbers, corner captions — drag the "Ignore small text" slider: filtered boxes fade out in real time, so just drag until only the subtitle stays highlighted.
Fine-Tune Subtitle Filtering by Color (Optional)
By default OCR reads every line of text inside your box. If the box still catches subtitle-sized clutter — a watermark or on-screen label sitting in the same area — turn on "Fine-tune subtitle filtering by color" in More settings. It adds a picker step where you isolate the real subtitle by its color. Leave it off and OCR simply reads everything in the box. (Filtering by font size is now built into the region-picker step via the "Ignore small text" slider — no need to enable this option for that.)

Sample the subtitle color
- Use the mouse to paint over the subtitle text area on the video frame; the system automatically collects the color at the painted positions
- Use the +/- buttons to zoom in/out for precise painting on small subtitles
- Made a mistake? Click "Clear Paint" to start over
- Once the minimum sample size is reached, the "Confirm Color" button becomes clickable
Try to paint directly on the subtitle text strokes and avoid the background area around them -- the more accurate the sampling, the better the recognition results.
Where did font-size filtering go?
Font-size filtering moved forward into the region-picker step: drag the "Ignore small text" slider and watch detection boxes fade in real time to drop small interfering text — no more typing pixel values here. The color picker now does one thing: color sampling.
Filter Out Another Language (Optional)
Some frames carry burned-in text in two scripts at once — for example a Japanese video with Chinese subtitles added on top, or on-screen signage in one language under a caption in another. The "Filter text" setting lets you exclude a whole script so OCR ignores it: pick the language you don't want (Japanese, Korean, Chinese, Thai, or Arabic) and that text is dropped, leaving just your subtitle line.
OCR Settings Explained
| Setting | Description | Recommendation |
|---|---|---|
| Source language | The language OCR reads on screen | Set it to the subtitle's language. Use the "Chinese + English" preset only for genuinely bilingual subtitles — it runs a slower extra English pass |
| Detection interval | How often GeekLink checks for a frame change — 0.1s (Finest) / 0.25s (Fine) / 0.3s (Accurate) / 0.5s (Standard) / 1.0s (Fast, less accurate) | The default suits most videos; drop to 0.1s for fast-flashing subtitles, at the cost of a longer run |
| Filter text | Exclude a whole script from the result — Thai, Japanese, Korean, Chinese, or Arabic | Use when the frame carries burned-in text in a language you don't want (e.g. a Japanese video with Chinese subtitles — filter out Japanese) |
| Fine-tune subtitle filtering by color | Off (default) = read every line inside your box. On = add a picker step that isolates the subtitle by its color and font size | Turn on for cluttered frames where a watermark, logo, or on-screen label sits inside the box and shares the subtitle's area |
FAQ
Why is the output full of garbled text?
The color sampling may not be precise enough, causing the OCR engine to treat background textures as text. Try re-sampling and paint only on the subtitle text strokes. You can also switch to a frame with clearer subtitles and try again. For a deeper guide on keeping only the subtitles and filtering out watermarks, logos, and on-screen text, see how to extract only the subtitles and how to ignore foreign-language logos.
What languages are supported?
OCR currently supports the following languages: English, Simplified Chinese, Traditional Chinese, Chinese-English bilingual, Japanese, Korean, Vietnamese, Spanish, Portuguese, French, German, Italian, and Indonesian.
Why are some subtitles not detected?
The detection interval may be too large, causing subtitles that flash by quickly to be missed. Try lowering the detection interval to 0.1s (Finest) to capture fast-flashing subtitles. The trade-off is a longer processing time.