TL;DR: Hardcoded (burned-in) subtitles are baked into the video image and can't be turned off, so to get editable text back you have to "read" the words off the picture (the technical name is OCR). In GeekLink you import the video, pick "Already on screen," draw a box around the subtitle area, and it runs locally on your Mac — it reads the text frame by frame into a timestamped SRT you can edit, translate, or re-burn. It's a free direct download from geeklink.dev (not the Mac App Store), runs fully offline, and handles Chinese, Japanese, Korean, English and more.
If you searched "extract hardcoded subtitles," you have a video where the captions are part of the picture — common with Chinese short dramas, Douyin/Bilibili reposts, DVD rips, and social clips. Here's exactly how to turn those baked-in captions back into an editable subtitle file.
What are hardcoded subtitles, and why can't you turn them off?
Hardcoded subtitles — also called hard subs, hardsubs, burned-in, or open captions — are text permanently rendered into the video frames during editing, so no player can hide them. Unlike soft subtitles (SRT/ASS files that ride alongside the video), there's no separate text track to grab.
To get an editable file, you have to read the text off the picture with OCR (Optical Character Recognition). This is the first step whenever you want to translate a video that only has burned-in captions — you can't translate what isn't text yet.
Hardcoded vs embedded subtitles: what's the difference?
Embedded subtitles are a separate text track hidden inside the video file — you can toggle them on or off, and you never need OCR to get them out. Hardcoded subtitles are painted into the picture and can't be toggled, which is exactly why they need OCR.
Quick way to tell which one you're holding:
- Can you switch the captions off in a player like VLC or QuickTime? Then they're embedded (also called soft or toggleable) — export the track directly, no OCR needed.
- Do the captions stay on screen no matter what — different player, different device, scrubbing around? Then they're hardcoded, and OCR is the only way to get editable text back.
Most Douyin/Bilibili reposts, short dramas, and social clips are hardcoded. If you're unsure which you have, see Embedded vs Burned-in vs External Subtitles.
How do you extract hardcoded subtitles, step by step?
The whole flow runs locally in GeekLink — your video never leaves your Mac.
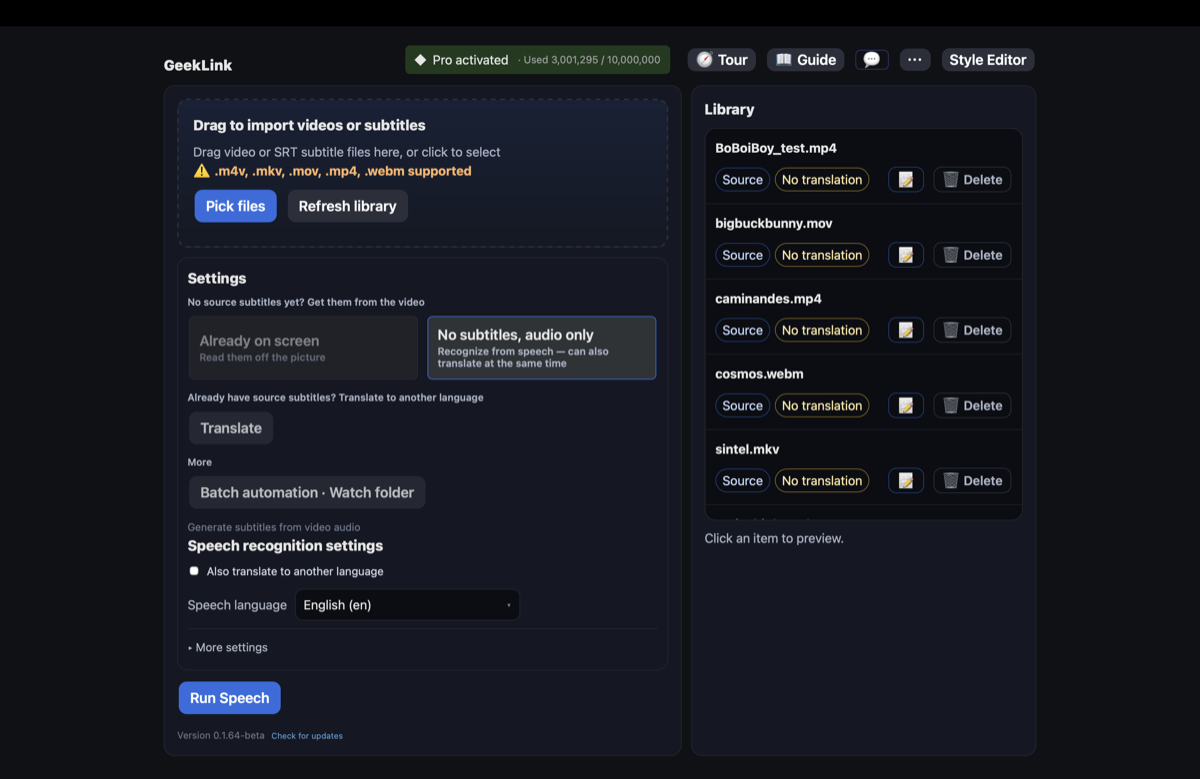
- Import the video — drop in the video with burned-in subtitles (MP4, MOV, MKV, and more).
- Pick "Already on screen — read them off the picture" — that's the option for video where the subtitles are baked into the image. (Behind the scenes it's OCR, but you don't need to know the term — the button is in plain language.)
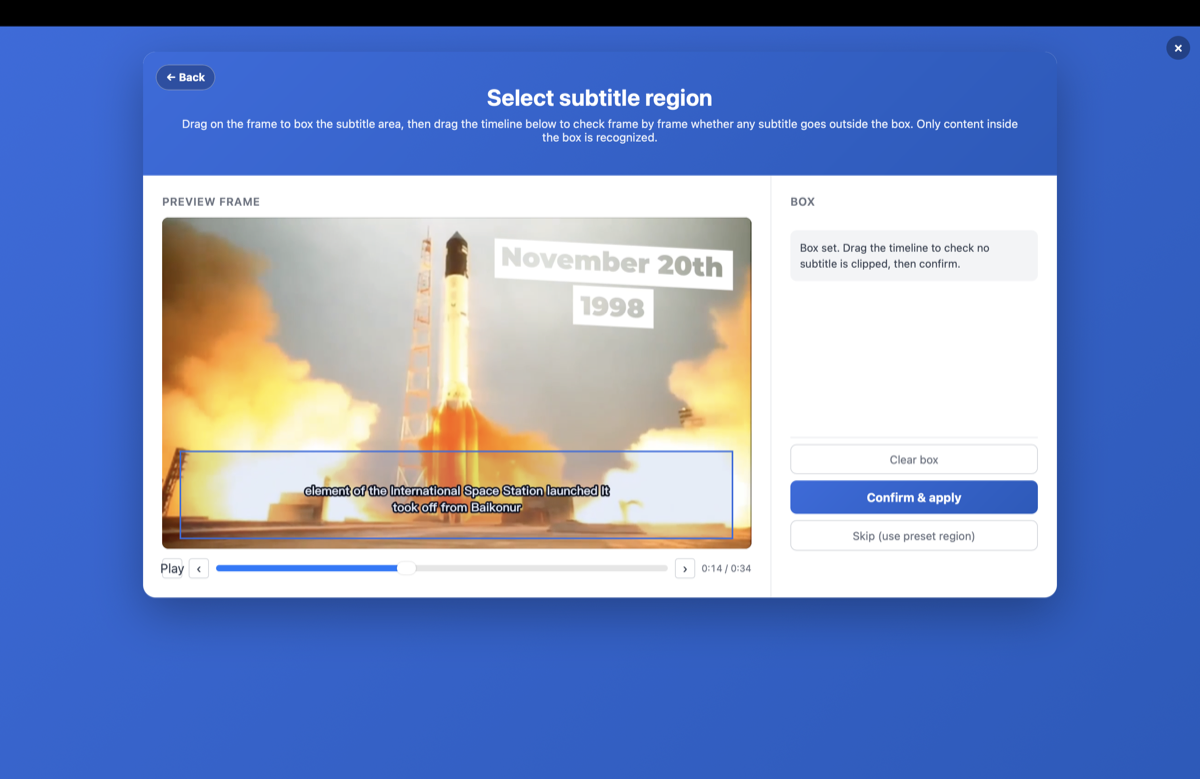
- Draw a box around the subtitle area — mark where the captions sit (usually the lower third). This is the key step: it tells OCR to ignore on-screen logos, watermarks, and other text, so you extract just the subtitle line.
- Run OCR extraction — GeekLink detects where the text changes between frames and builds a timestamped subtitle file, all on your Mac.
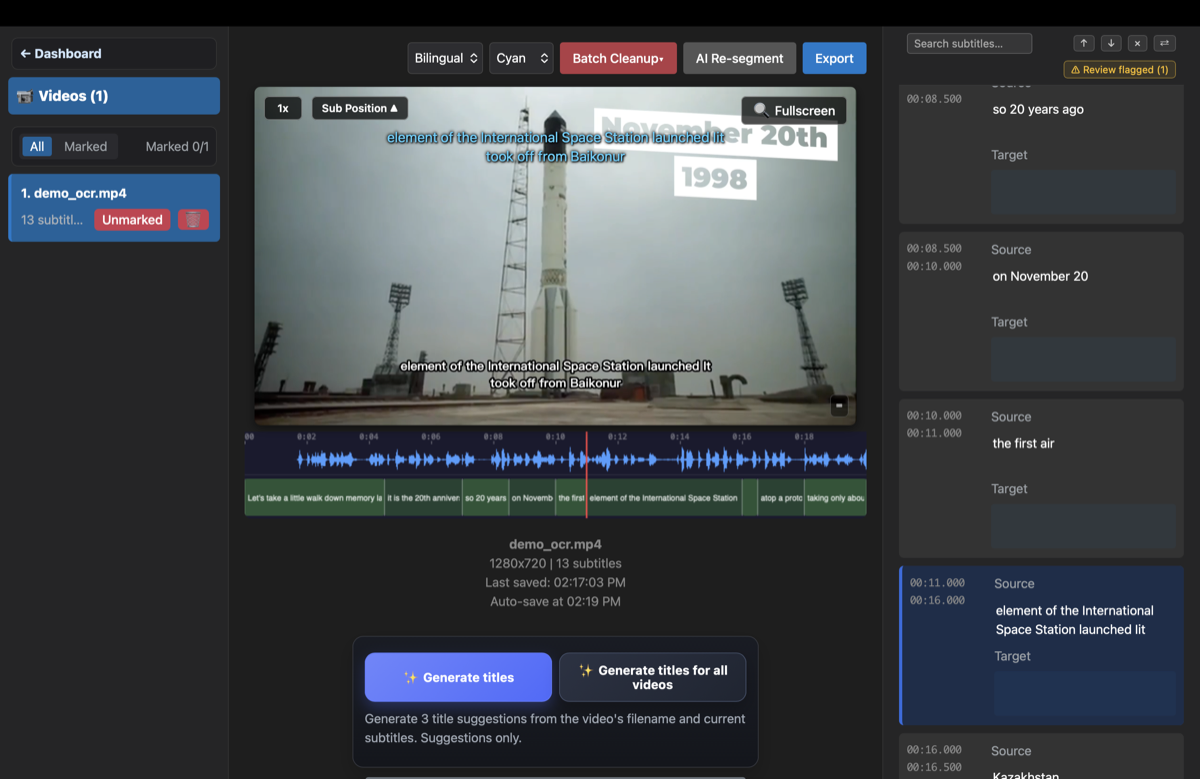
- Review and export — fix any OCR slips in the built-in editor (it flags the lines worth checking), then export SRT — or translate to another language and burn new subtitles in.
How do you extract subtitles from an MP4?
First check whether the MP4's subtitles are a real text track or burned into the picture — that one answer decides your tool. MP4 is just a container and can hold either kind.
- If the captions can be turned off in a player, the MP4 carries a soft subtitle track — you can pull the SRT straight out, no OCR involved.
- If they're always on screen, they're hardcoded — import the MP4 into GeekLink, pick "Already on screen," box the subtitle area, and run OCR (the five steps above). The exact same flow works for MOV, MKV, and TS files.
How do you stop OCR from grabbing logos and watermarks?
News clips, short dramas, and reposts are full of on-screen clutter — channel logos, "NEWS" badges, big background graphics. You only want the subtitle line.
Beyond drawing the box, GeekLink can filter by font size and color — so OCR keeps only the text that looks like a subtitle and drops everything else. It detects every piece of text on the frame and labels its size; you brush over the real subtitle to sample its color. Then OCR keeps, say, the small white caption line and ignores the giant logo and the watermark.

How do you extract hardcoded subtitles from anime?
Anime fansubs are usually hardcoded, often with stylized fonts, colored text, and karaoke or sign typesetting — draw the box tightly around the bottom dialogue line so OCR skips the signs and effects.
- Box only the dialogue line at the bottom, so top-of-screen sign translations and karaoke lyrics don't get mixed into your subtitles.
- Japanese and Chinese subs: GeekLink's CJK models read kanji, kana, and hanzi that generic OCR mangles.
- If the raw has clean Japanese audio and the burned-in text is heavily styled, speech recognition (Whisper) can be the faster path — GeekLink does both, so you can compare.
How accurate is OCR, and how do you get the best results?
For clean subtitles at 720p or higher, OCR typically lands around 90–98% accurate — and GeekLink's built-in editor lets you fix the rest fast by flagging only the lines it's unsure about, so you don't re-read every line.
To get the best results:
- Use high-resolution video (720p+) — more pixels per character means cleaner reads.
- Make sure subtitles have good contrast against the background.
- Draw the region box so the subtitle line is isolated from logos, watermarks, and on-screen graphics.
- For Chinese / Japanese / Korean, GeekLink uses specialized CJK models that beat generic OCR.
When the burned-in text is too small or blurry but the audio is clean, speech recognition (Whisper) can be the better path — GeekLink does both.
Can I extract subtitles from any video?
Almost — if a person can read the captions on screen, OCR can usually extract them. The limits are readability, not file format.
- Works well: clean burned-in subtitles at 720p or higher, in any language, in any container (MP4, MOV, MKV).
- Harder: very low resolution, heavy compression artifacts, moving or animated text, or captions over busy backgrounds with poor contrast.
- No text on screen at all? There's nothing for OCR to read — use speech recognition to transcribe the audio instead.
Why use GeekLink for OCR extraction?
- 100% local: OCR runs entirely on your Mac — no uploading your video to a cloud service.
- Multi-script: Chinese (simplified/traditional), Japanese (kanji + kana), Korean (Hangul), Arabic (RTL), and Latin scripts.
- Draw-a-box region select: extract just the subtitle line, not the logos and watermarks around it.
- Flags the lines worth checking: you review a small handful instead of reading every cue.
- One workflow: extract → edit → translate → burn-in, without switching tools.
Frequently Asked Questions
What are hardcoded subtitles?
Hardcoded (burned-in) subtitles are text permanently rendered into the video image during editing. Unlike soft subtitles (SRT/ASS files), they cannot be turned off in the player.
Can OCR extract subtitles from any language?
GeekLink's OCR supports Chinese, Japanese, Korean, English, and most Latin-script languages. Arabic and Thai are also supported with specialized models.
How accurate is OCR vs speech recognition?
OCR accuracy depends on video quality and subtitle clarity — typically 90-98% for clean subtitles at 720p+. Speech recognition (Whisper) is better when the burned-in text is unclear but the audio is clean.
Can I remove hardcoded subtitles from a video?
GeekLink extracts the text as a subtitle file but does not erase the visual subtitles from the video. To "replace" them, overlay new translated subtitles on top.
Does my video get uploaded anywhere?
No. OCR runs locally on your Mac — the video never leaves your device.
Is GeekLink on the Mac App Store?
No. GeekLink is a free direct download from geeklink.dev — it is not on the Mac App Store. Get the DMG from the website; no App Store, no account, and no login required.
Are the subtitle timings accurate?
Yes. GeekLink detects, frame by frame, when each subtitle line appears and disappears, so the exported SRT is time-aligned to the video — useful even if you only care about the timing and not perfect text (e.g. making subs2srs cards for language learning).
How do I extract subtitles from an MP4?
Check whether the MP4's captions can be toggled off in a player. If they can, it's a soft track you can export directly. If they stay on screen no matter what, they're hardcoded — import the MP4 into GeekLink, choose "Already on screen," box the subtitle area, and run OCR. The same works for MOV, MKV, and TS.
Can I extract subtitles from anime?
Yes. Anime fansubs are usually hardcoded. Draw the box tightly around the bottom dialogue line so OCR ignores sign translations and karaoke effects. GeekLink's CJK models handle Japanese and Chinese text well, and if the audio is clean you can use speech recognition instead.
Related Articles
Disclosure: GeekLink is our own product. OCR accuracy figures are typical ranges for clean 720p+ subtitles and vary with video quality.