要点:焼き込み字幕(ハードサブ)は動画の映像そのものに焼き付けられていてオフにできません。そのため編集可能なテキストを取り戻すには、画面の文字を「読み取る」必要があります(技術的にはこれをOCRと呼びます)。GeekLinkでは動画を取り込み、「すでに画面にある」を選び、字幕エリアを枠で囲むだけ。あとはお使いのMac上でローカルに動作し、フレームごとに文字を読み取って、編集・翻訳・再焼き込みできるタイムスタンプ付きSRTに仕上げます。ダウンロード無料、完全オフライン動作で、中国語・日本語・韓国語・英語などに対応します。
「焼き込み字幕 抽出」で検索したあなたは、字幕が映像の一部になっている動画をお持ちのはずです——中国のショートドラマ、Douyin/Bilibiliの転載、DVDリップ、SNSのクリップなどでよく見られます。ここでは、その焼き込み字幕を編集可能な字幕ファイルに戻す具体的な方法を解説します。
焼き込み字幕とは何か、なぜオフにできないのか?
焼き込み字幕——ハードサブやオープンキャプションとも呼ばれます——は、編集時に動画のフレームへ恒久的に描き込まれた文字で、どのプレーヤーでも非表示にできません。ソフト字幕(動画と別に付随するSRT/ASSファイル)とは異なり、取り出せる独立したテキストトラックが存在しません。
編集可能なファイルを得るには、OCR(光学文字認識)で画面から文字を読み取る必要があります。これは焼き込み字幕しかない動画を翻訳したいときの最初のステップです——まだテキストになっていないものは翻訳できないからです。
焼き込み字幕を抽出する手順は?
すべての処理はGeekLink内でローカルに完結します——動画がMacの外に出ることはありません。
- 動画を取り込む——焼き込み字幕入りの動画をドロップします(MP4、MOV、MKVなど)。
- 「すでに画面にある — 画面から認識」を選ぶ——字幕が映像に焼き込まれている動画向けのオプションです。(裏側ではOCRが動いていますが、用語を知る必要はありません——ボタンはわかりやすい言葉で書かれています。)
- 字幕エリアを枠で囲む——字幕がどこにあるか(通常は画面下部3分の1)をマークします。これが肝心なステップです:画面上のロゴ・透かし・その他の文字を無視するようOCRに伝え、字幕の行だけを抽出できます。
- OCR抽出を実行する——GeekLinkがフレーム間で文字が変わる箇所を検出し、タイムスタンプ付きの字幕ファイルを構築します。すべてMac上で完結します。
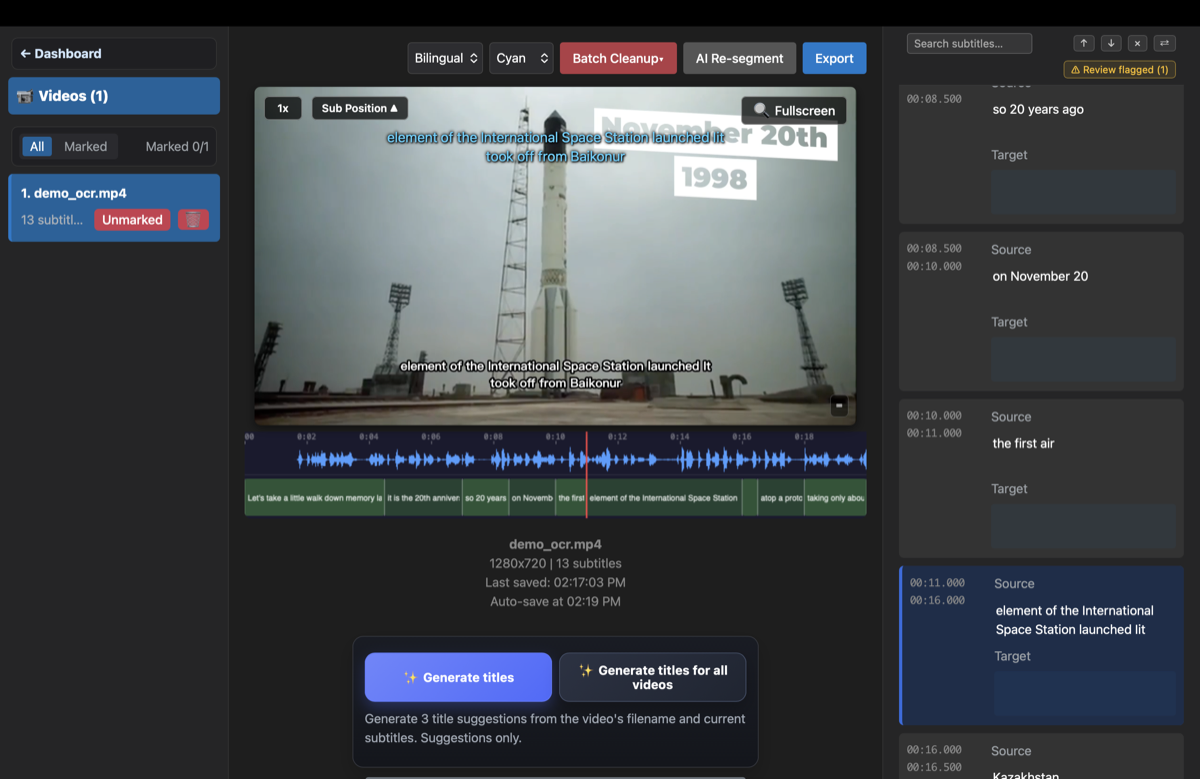
- 確認して書き出す——内蔵エディタでOCRの誤りを修正し(確認すべき行を自動でフラグ表示します)、SRTを書き出します——あるいは別言語に翻訳して新しい字幕を焼き込むこともできます。
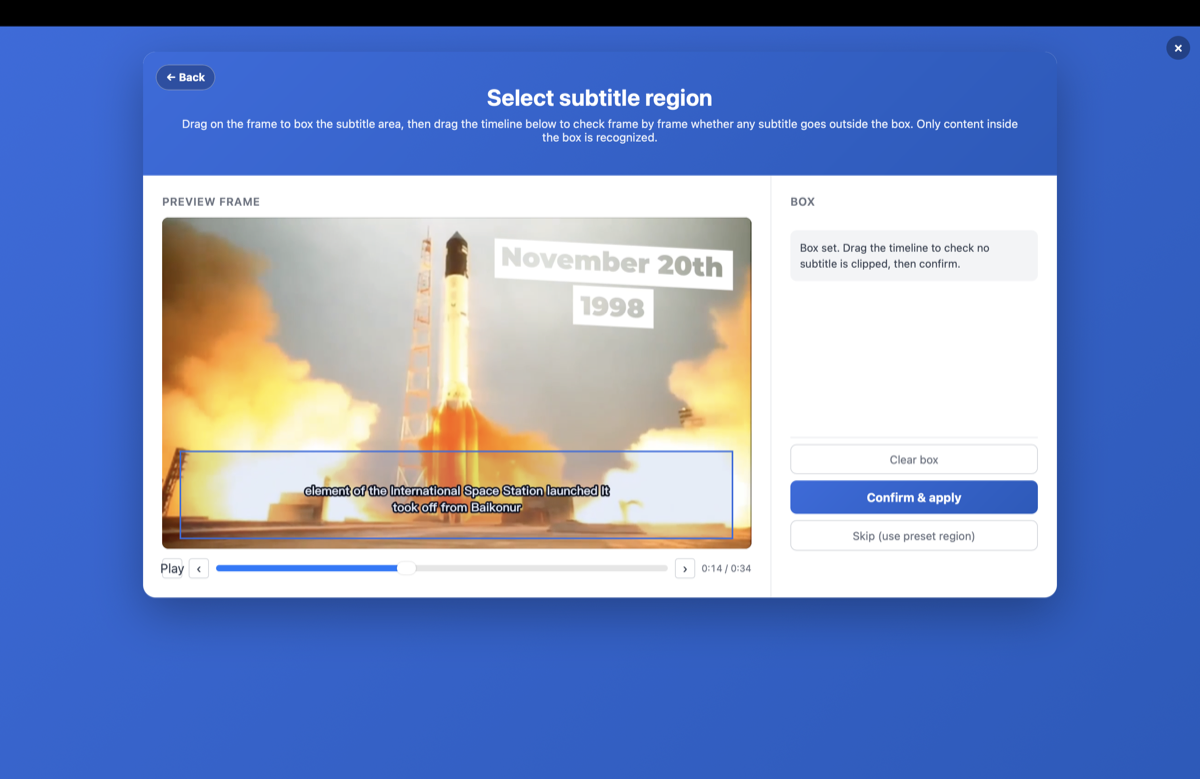
OCRがロゴや透かしを拾わないようにするには?
ニュースのクリップ、ショートドラマ、転載動画は、画面上のノイズだらけです——チャンネルロゴ、「NEWS」バッジ、大きな背景グラフィック。欲しいのは字幕の行だけです。
枠で囲むことに加えて、GeekLinkは文字サイズと色でフィルタリングできます——OCRは字幕らしく見える文字だけを残し、それ以外をすべて捨てます。フレーム上のすべての文字を検出してサイズをラベル付けし、本物の字幕をなぞってその色をサンプリングします。すると、たとえば小さな白い字幕の行だけを残し、巨大なロゴや透かしを無視します。

OCRの精度はどれくらいか、ベストな結果を得るには?
720p以上のきれいな字幕なら、OCRの精度は通常およそ90〜98%に達します——そしてGeekLinkの内蔵エディタは、確信の持てない行だけをフラグ表示するので、残りをすばやく修正できます。すべての行を読み直す必要はありません。
ベストな結果を得るには:
- 高解像度の動画(720p以上)を使う——文字あたりのピクセルが多いほど、読み取りがクリーンになります。
- 字幕が背景に対して十分なコントラストを持つようにする。
- エリアの枠を描く——字幕の行をロゴ・透かし・画面グラフィックから切り離します。
- 中国語・日本語・韓国語の場合、GeekLinkは汎用OCRを上回る専用のCJKモデルを使用します。
焼き込み文字が小さすぎたりぼやけていても音声がクリアな場合は、音声認識(Whisper)の方が良い選択肢になることもあります——GeekLinkはどちらにも対応しています。
OCR抽出にGeekLinkを使う理由は?
- 100%ローカル:OCRはすべてMac上で動作します——動画をクラウドサービスにアップロードしません。
- 多言語スクリプト対応:中国語(簡体字/繁体字)、日本語(漢字+かな)、韓国語(ハングル)、アラビア語(RTL)、ラテン文字。
- 枠で囲むエリア選択:周りのロゴや透かしではなく、字幕の行だけを抽出します。
- 確認すべき行をフラグ表示:すべてのキューを読む代わりに、ほんの一握りだけを確認すれば済みます。
- ひとつのワークフロー:抽出 → 編集 → 翻訳 → 焼き込みまで、ツールを切り替えずに完結します。
よくある質問
焼き込み字幕とは何ですか?
焼き込み字幕(ハードサブ)は、編集時に動画の映像へ恒久的に描き込まれた文字です。ソフト字幕(SRT/ASSファイル)とは異なり、プレーヤーでオフにできません。
OCRはどんな言語の字幕でも抽出できますか?
GeekLinkのOCRは中国語、日本語、韓国語、英語、そしてほとんどのラテン文字言語に対応しています。アラビア語やタイ語も専用モデルで対応しています。
OCRと音声認識ではどちらが正確ですか?
OCRの精度は動画の品質と字幕の鮮明さに依存します——720p以上のきれいな字幕で通常90〜98%です。焼き込み文字が不鮮明でも音声がクリアな場合は、音声認識(Whisper)の方が優れています。
動画から焼き込み字幕を消すことはできますか?
GeekLinkはテキストを字幕ファイルとして抽出しますが、動画から視覚的な字幕を消去することはありません。「置き換える」には、新しい翻訳字幕を上に重ねます。
私の動画はどこかにアップロードされますか?
いいえ。OCRはお使いのMac上でローカルに動作します——動画がデバイスの外に出ることはありません。
関連記事
開示:GeekLinkは当社自身の製品です。OCRの精度の数値は720p以上のきれいな字幕での一般的な範囲であり、動画の品質によって変動します。