太长不看:硬字幕(烧录字幕)是直接烤进视频画面里的,关不掉,所以要想拿回可编辑的文字,就得把字「从画面里读出来」(技术名称叫 OCR)。在 GeekLink 里,你导入视频,选择「字幕已经印在画面上」,框选字幕区域,它就会在你的 Mac 上本地运行——逐帧把文字识别成带时间轴的 SRT,你可以编辑、翻译,或者重新烧录。免费下载,完全离线运行,支持中文、日文、韩文、英文等多种语言。
如果你搜索了「提取硬字幕」,说明你手上有一段字幕是画面一部分的视频——这在中国短剧、抖音/B站搬运、DVD 转录和社交媒体片段里很常见。下面就讲清楚,如何把这些烤进画面的字幕还原成可编辑的字幕文件。
什么是硬字幕?为什么关不掉?
硬字幕——也叫烧录字幕或开放式字幕——是在剪辑时永久渲染进视频帧里的文字,任何播放器都无法隐藏。和软字幕(与视频并行的 SRT/ASS 文件)不同,它没有一条单独的文字轨道可供提取。
要拿到可编辑的文件,你必须用 OCR(光学字符识别)把文字从画面里读出来。每当你想翻译一段只有烧录字幕的视频时,这都是第一步——还没变成文字的东西,你没法翻译。
如何一步步提取硬字幕?
整个流程都在 GeekLink 里本地完成——你的视频永远不会离开你的 Mac。
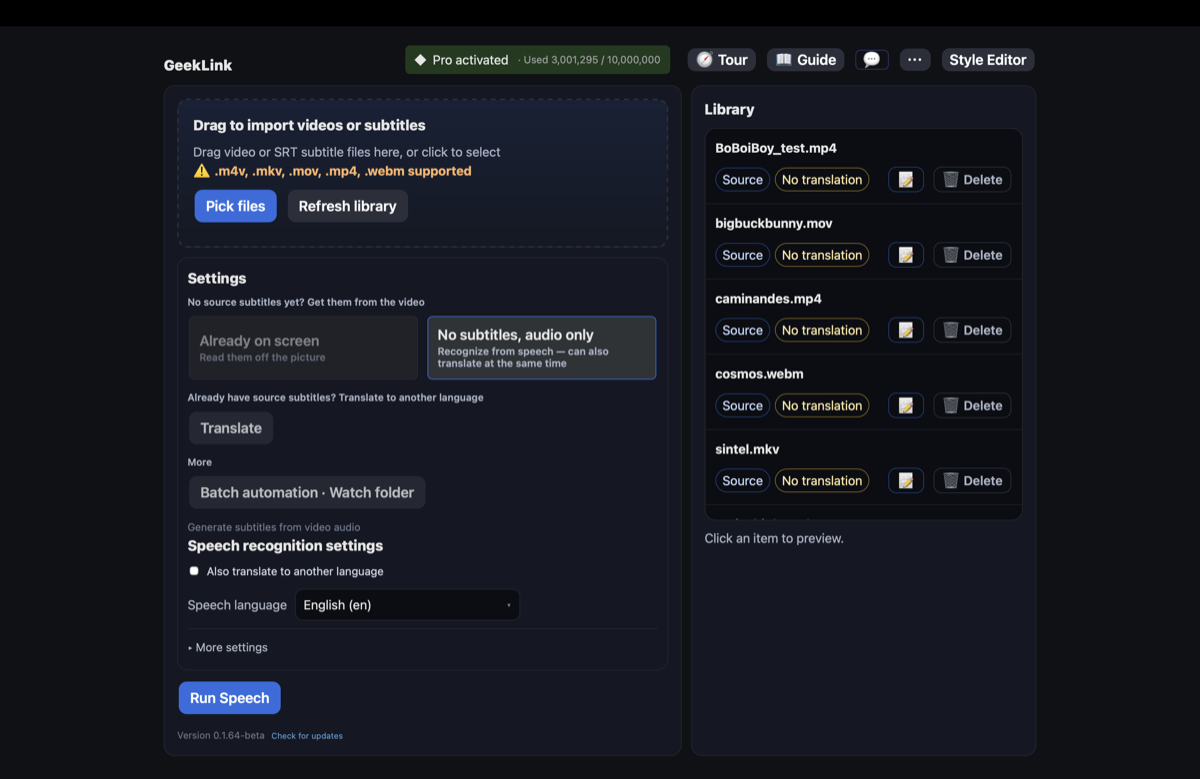
- 导入视频——把带烧录字幕的视频拖进来(支持 MP4、MOV、MKV 等格式)。
- 选择「字幕已经印在画面上 — 从画面里识别出来」——这是为字幕烤进画面的视频准备的选项。(背后用的是 OCR,但你不需要知道这个术语——按钮用的是大白话。)
- 框选字幕区域——标出字幕所在的位置(通常在画面下方三分之一处)。这是关键一步:它告诉 OCR 忽略画面上的台标、水印和其他文字,让你只提取字幕那一行。
- 运行 OCR 提取——GeekLink 会检测帧与帧之间文字何处发生变化,并构建一个带时间轴的字幕文件,全程都在你的 Mac 上完成。
- 复查并导出——在内置编辑器里修正 OCR 的零星错误(它会标出值得检查的行),然后导出 SRT——或者翻译成另一种语言,再烧录新的字幕。
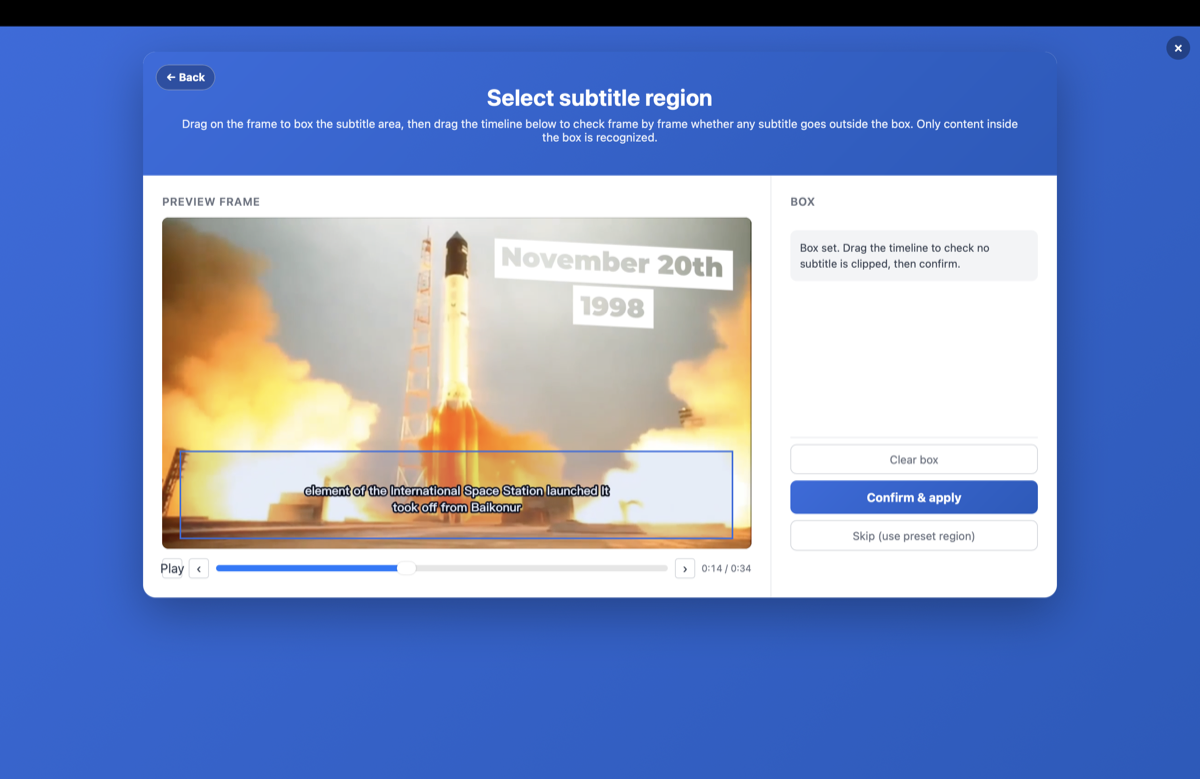
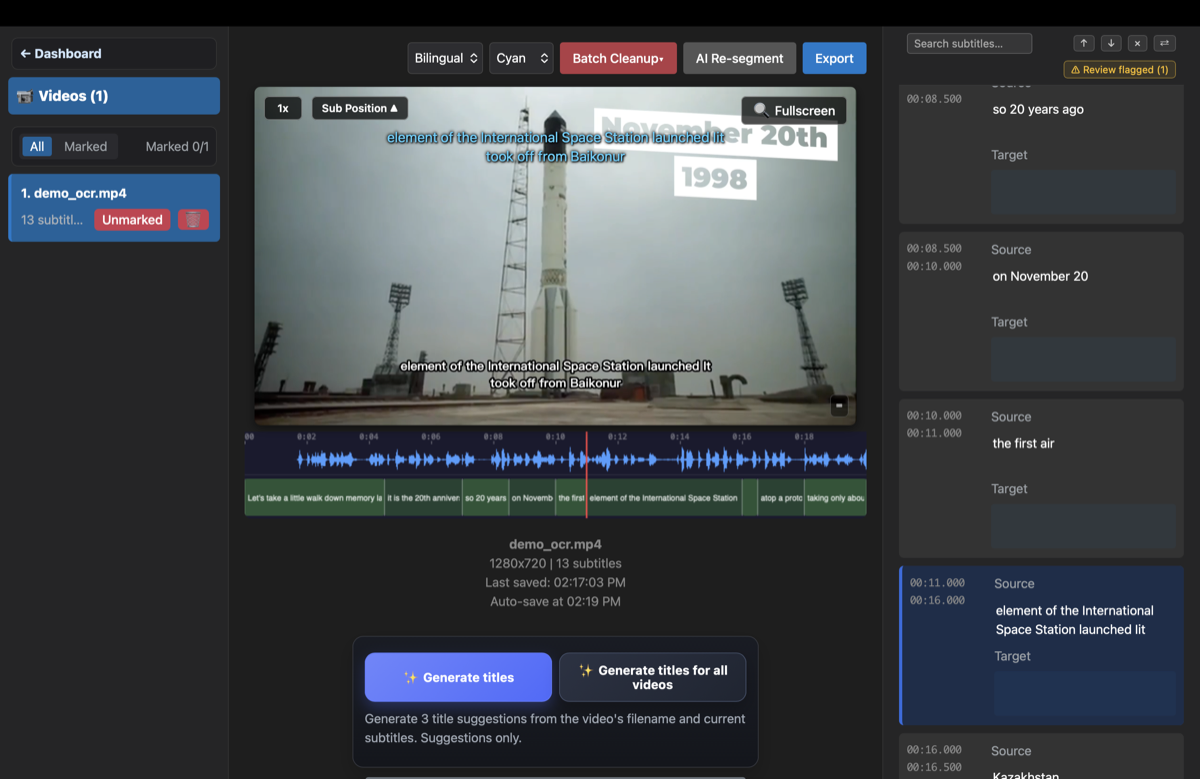
怎样防止 OCR 把台标和水印也识别进来?
新闻片段、短剧和搬运视频里满是画面杂物——频道台标、「NEWS」角标、巨大的背景图形。你只想要字幕那一行。
除了框选区域,GeekLink 还能按字号和颜色过滤——让 OCR 只保留看起来像字幕的文字,丢掉其余一切。它会检测画面上的每一处文字并标注其大小;你在真正的字幕上涂抹一下,采样它的颜色。然后 OCR 就只保留比如那行白色的小字幕,忽略巨大的台标和水印。

OCR 的准确率如何?怎样才能得到最好的效果?
对于 720p 及以上分辨率的清晰字幕,OCR 的准确率通常在 90–98% 左右——而 GeekLink 的内置编辑器只标出它没把握的行,让你快速修正剩下的部分,不用逐行重读。
要想得到最好的效果:
- 使用高分辨率视频(720p 以上)——每个字符占的像素越多,识别越干净。
- 确保字幕与背景有良好的对比度。
- 框选区域,让字幕行与台标、水印和画面图形隔离开。
- 对于中文 / 日文 / 韩文,GeekLink 使用专门的 CJK 模型,效果优于通用 OCR。
当烧录文字太小或太模糊,但音频清晰时,语音识别(Whisper)可能是更好的路径——GeekLink 两者都能做。
为什么用 GeekLink 做 OCR 提取?
- 100% 本地:OCR 完全在你的 Mac 上运行——不会把你的视频上传到云服务。
- 多种文字:中文(简体/繁体)、日文(汉字 + 假名)、韩文(谚文)、阿拉伯文(从右往左)以及拉丁文字。
- 框选区域:只提取字幕那一行,不要周围的台标和水印。
- 标出值得检查的行:你只复查一小撮,而不是逐条阅读。
- 一站式流程:提取 → 编辑 → 翻译 → 烧录,无需切换工具。
常见问题
什么是硬字幕?
硬字幕(烧录字幕)是剪辑时永久渲染进视频画面里的文字。和软字幕(SRT/ASS 文件)不同,它在播放器里无法关闭。
OCR 能提取任何语言的字幕吗?
GeekLink 的 OCR 支持中文、日文、韩文、英文以及大多数拉丁文字语言。阿拉伯文和泰文也有专门的模型支持。
OCR 和语音识别相比,准确率如何?
OCR 的准确率取决于视频质量和字幕清晰度——720p 以上的清晰字幕通常为 90-98%。当烧录文字不清晰但音频清晰时,语音识别(Whisper)效果更好。
我能从视频里去掉硬字幕吗?
GeekLink 会把文字提取成字幕文件,但不会从视频里抹掉画面上的字幕。要想「替换」它们,可以在上面叠加新的译文字幕。
我的视频会被上传到什么地方吗?
不会。OCR 在你的 Mac 上本地运行——视频永远不会离开你的设备。
相关文章
声明:GeekLink 是我们自己的产品。OCR 准确率数据是 720p 以上清晰字幕的典型区间,会随视频质量而变化。