요약: 하드코딩(번인) 자막은 영상 화면 자체에 새겨져 있어 끌 수 없습니다. 그래서 편집 가능한 텍스트로 되돌리려면 화면에서 글자를 "읽어내야" 합니다(기술 용어로 OCR). GeekLink에서는 영상을 가져오고 "이미 화면에 있음"을 선택한 뒤, 자막 영역에 박스를 그리면 Mac에서 로컬로 실행됩니다 — 프레임 단위로 텍스트를 읽어 타임스탬프가 붙은 SRT로 만들어 주며, 이를 편집하거나 번역하거나 다시 번인할 수 있습니다. 무료로 다운로드, 완전 오프라인 실행, 한국어·중국어·일본어·영어 등 다양한 언어를 지원합니다.
"하드코딩 자막 추출"을 검색하셨다면, 자막이 화면의 일부로 박혀 있는 영상을 가지고 계실 겁니다 — 중국 숏드라마, 더우인/빌리빌리 재업로드, DVD 립, SNS 클립에서 흔히 볼 수 있죠. 이렇게 새겨진 자막을 편집 가능한 자막 파일로 되돌리는 정확한 방법을 알려드립니다.
하드코딩 자막이란 무엇이며, 왜 끌 수 없을까?
하드코딩 자막 — 번인 자막 또는 오픈 캡션이라고도 합니다 — 은 편집 과정에서 영상 프레임에 영구적으로 렌더링된 텍스트라서, 어떤 플레이어로도 숨길 수 없습니다. 영상과 나란히 따라다니는 소프트 자막(SRT/ASS 파일)과 달리, 따로 가져올 수 있는 텍스트 트랙이 없습니다.
편집 가능한 파일을 얻으려면 OCR(광학 문자 인식)로 화면에서 텍스트를 읽어내야 합니다. 번인 자막만 있는 영상을 번역하려고 할 때 이것이 첫 단계입니다 — 아직 텍스트가 아닌 것은 번역할 수 없으니까요.
하드코딩 자막을 단계별로 어떻게 추출할까?
전체 과정은 GeekLink에서 로컬로 실행됩니다 — 영상은 절대 Mac 밖으로 나가지 않습니다.
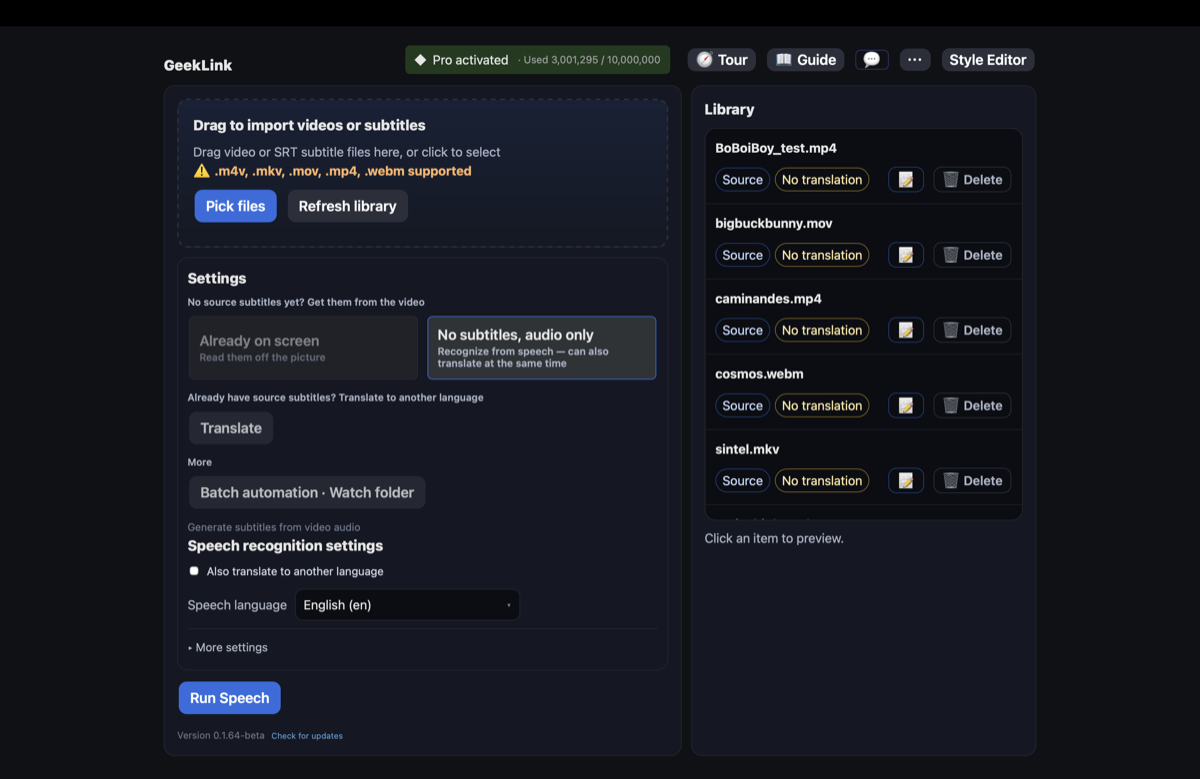
- 영상 가져오기 — 번인 자막이 있는 영상을 끌어다 놓으세요(MP4, MOV, MKV 등).
- "이미 화면에 있음 — 화면에서 인식" 선택 — 자막이 화면에 박혀 있는 영상을 위한 옵션입니다. (내부적으로는 OCR이지만 용어를 몰라도 됩니다 — 버튼이 쉬운 말로 되어 있습니다.)
- 자막 영역에 박스 그리기 — 자막이 있는 위치(보통 화면 하단 1/3)를 표시하세요. 이것이 핵심 단계입니다: OCR에게 화면 속 로고, 워터마크, 다른 텍스트를 무시하라고 알려주어 자막 줄만 추출하게 합니다.
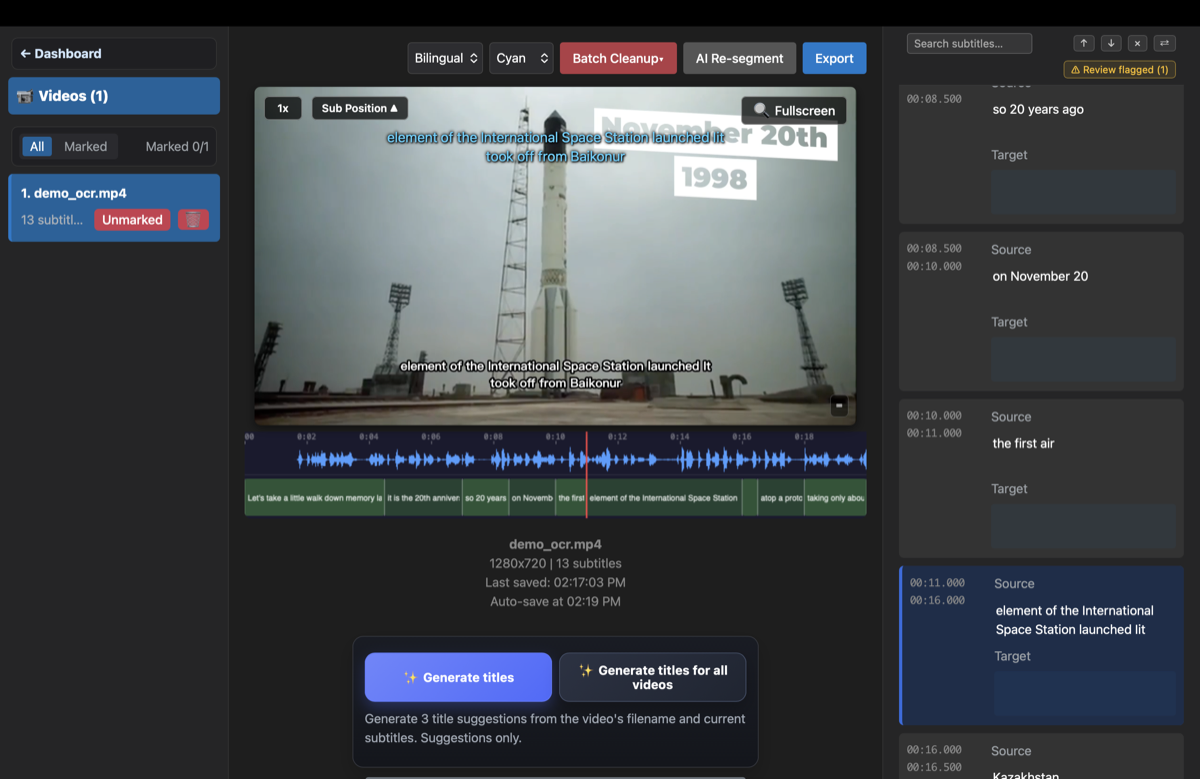
- OCR 추출 실행 — GeekLink가 프레임 간 텍스트 변화를 감지해 타임스탬프가 붙은 자막 파일을 만듭니다 — 모두 Mac에서요.
- 검토 후 내보내기 — 내장 편집기에서 OCR 오류를 수정하고(확인할 가치가 있는 줄을 표시해 줍니다) SRT로 내보내거나 — 다른 언어로 번역해 새 자막을 번인하세요.
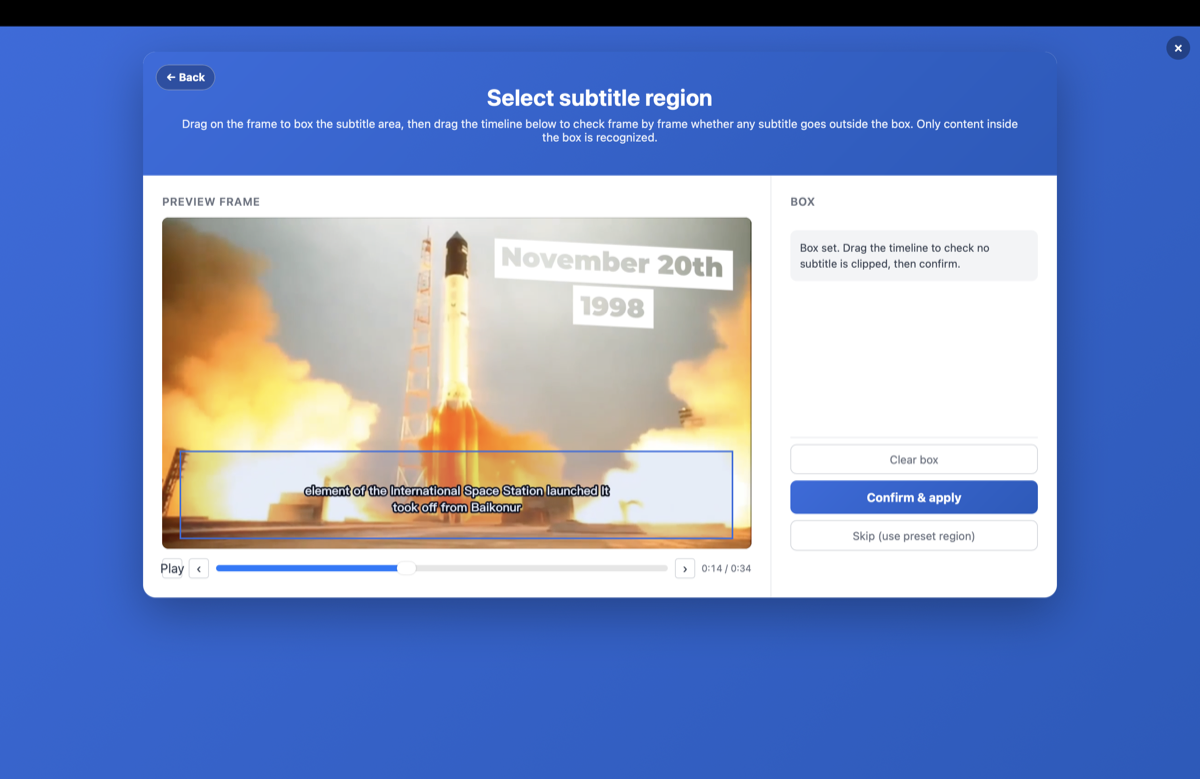
OCR이 로고와 워터마크를 인식하지 않게 하려면?
뉴스 클립, 숏드라마, 재업로드 영상에는 화면 잡동사니가 가득합니다 — 채널 로고, "NEWS" 배지, 큰 배경 그래픽 등이요. 여러분이 원하는 건 자막 줄뿐입니다.
박스 그리기 외에도, GeekLink는 글자 크기와 색상으로 필터링할 수 있습니다 — 그래서 OCR이 자막처럼 보이는 텍스트만 남기고 나머지는 버립니다. 프레임의 모든 텍스트를 감지해 크기를 표시하고, 실제 자막 위를 칠해 색상을 샘플링합니다. 그러면 OCR은 예를 들어 작은 흰색 자막 줄은 남기고 거대한 로고와 워터마크는 무시합니다.

OCR은 얼마나 정확하며, 최상의 결과를 얻으려면?
720p 이상의 깨끗한 자막이라면 OCR은 보통 약 90~98% 정확도를 보입니다 — 그리고 GeekLink의 내장 편집기는 확신이 서지 않는 줄만 표시해 주어 나머지를 빠르게 수정할 수 있게 하므로, 모든 줄을 다시 읽을 필요가 없습니다.
최상의 결과를 얻으려면:
- 고해상도 영상(720p+) 사용 — 글자당 픽셀이 많을수록 더 깨끗하게 읽힙니다.
- 자막이 배경과 충분히 대비되도록 하세요.
- 영역 박스를 그려 자막 줄을 로고, 워터마크, 화면 그래픽으로부터 분리하세요.
- 중국어 / 일본어 / 한국어의 경우, GeekLink는 일반 OCR을 능가하는 전용 CJK 모델을 사용합니다.
번인된 텍스트가 너무 작거나 흐릿하지만 음성이 깨끗하다면, 음성 인식(Whisper)이 더 나은 방법일 수 있습니다 — GeekLink는 둘 다 지원합니다.
OCR 추출에 GeekLink를 쓰는 이유는?
- 100% 로컬: OCR은 전적으로 Mac에서 실행됩니다 — 영상을 클라우드 서비스에 업로드하지 않습니다.
- 다중 문자 체계: 중국어(간체/번체), 일본어(한자 + 가나), 한국어(한글), 아랍어(RTL), 라틴 문자.
- 박스 그리기 영역 선택: 주변의 로고와 워터마크가 아니라 자막 줄만 추출합니다.
- 확인할 가치가 있는 줄 표시: 모든 자막을 읽는 대신 소수만 검토하면 됩니다.
- 하나의 워크플로: 추출 → 편집 → 번역 → 번인까지 도구를 바꾸지 않고요.
자주 묻는 질문
하드코딩 자막이란 무엇인가요?
하드코딩(번인) 자막은 편집 과정에서 영상 화면에 영구적으로 렌더링된 텍스트입니다. 소프트 자막(SRT/ASS 파일)과 달리 플레이어에서 끌 수 없습니다.
OCR로 어떤 언어든 자막을 추출할 수 있나요?
GeekLink의 OCR은 중국어, 일본어, 한국어, 영어, 그리고 대부분의 라틴 문자 언어를 지원합니다. 아랍어와 태국어도 전용 모델로 지원됩니다.
OCR과 음성 인식 중 어느 쪽이 더 정확한가요?
OCR 정확도는 영상 품질과 자막 선명도에 따라 달라집니다 — 720p+ 깨끗한 자막의 경우 보통 90~98%입니다. 번인된 텍스트가 불분명하지만 음성이 깨끗할 때는 음성 인식(Whisper)이 더 낫습니다.
영상에서 하드코딩 자막을 제거할 수 있나요?
GeekLink는 텍스트를 자막 파일로 추출하지만 영상에서 보이는 자막을 지우지는 않습니다. "교체"하려면 번역된 새 자막을 위에 덧씌우세요.
제 영상이 어딘가로 업로드되나요?
아니요. OCR은 Mac에서 로컬로 실행됩니다 — 영상은 절대 기기 밖으로 나가지 않습니다.
관련 글
고지: GeekLink는 저희가 만든 제품입니다. OCR 정확도 수치는 깨끗한 720p+ 자막의 일반적인 범위이며 영상 품질에 따라 달라집니다.