En resumen: los subtítulos incrustados (quemados) están grabados en la imagen del video y no se pueden desactivar, así que para recuperar el texto editable tienes que "leer" las palabras desde la imagen (el nombre técnico es OCR). En GeekLink importas el video, eliges "Ya en pantalla", dibujas un recuadro alrededor del área de subtítulos y se ejecuta localmente en tu Mac: lee el texto fotograma a fotograma y lo convierte en un SRT con marcas de tiempo que puedes editar, traducir o volver a quemar. Descarga gratuita, funciona totalmente sin conexión y admite chino, japonés, coreano, inglés y más.
Si buscaste "extraer subtítulos incrustados", tienes un video donde los subtítulos forman parte de la imagen, algo común en los dramas cortos chinos, en las reediciones de Douyin/Bilibili, en los rips de DVD y en los clips de redes sociales. Aquí te explicamos exactamente cómo convertir esos subtítulos quemados de nuevo en un archivo de subtítulos editable.
¿Qué son los subtítulos incrustados y por qué no se pueden desactivar?
Los subtítulos incrustados —también llamados quemados o abiertos— son texto renderizado de forma permanente en los fotogramas del video durante la edición, por lo que ningún reproductor puede ocultarlos. A diferencia de los subtítulos blandos (archivos SRT/ASS que acompañan al video), no hay una pista de texto independiente que tomar.
Para obtener un archivo editable, tienes que leer el texto desde la imagen con OCR (reconocimiento óptico de caracteres). Este es el primer paso siempre que quieras traducir un video que solo tiene subtítulos quemados: no puedes traducir lo que todavía no es texto.
¿Cómo se extraen los subtítulos incrustados, paso a paso?
Todo el flujo se ejecuta localmente en GeekLink: tu video nunca sale de tu Mac.
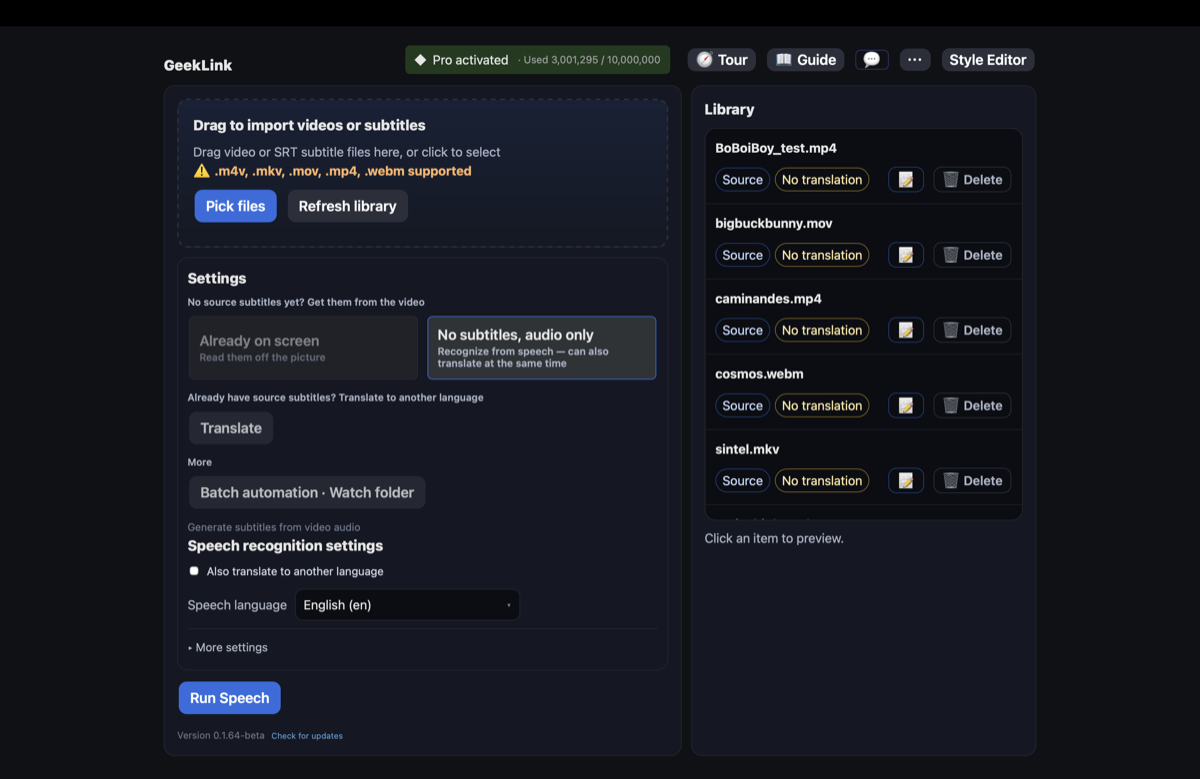
- Importa el video: arrastra el video con subtítulos quemados (MP4, MOV, MKV y más).
- Elige «Ya en pantalla — léelos de la imagen»: esa es la opción para videos donde los subtítulos están grabados en la imagen. (Por detrás es OCR, pero no necesitas conocer el término; el botón está en lenguaje sencillo.)
- Dibuja un recuadro alrededor del área de subtítulos: marca dónde están los subtítulos (normalmente en el tercio inferior). Este es el paso clave: le indica al OCR que ignore los logos, las marcas de agua y demás texto en pantalla, para que extraigas solo la línea del subtítulo.
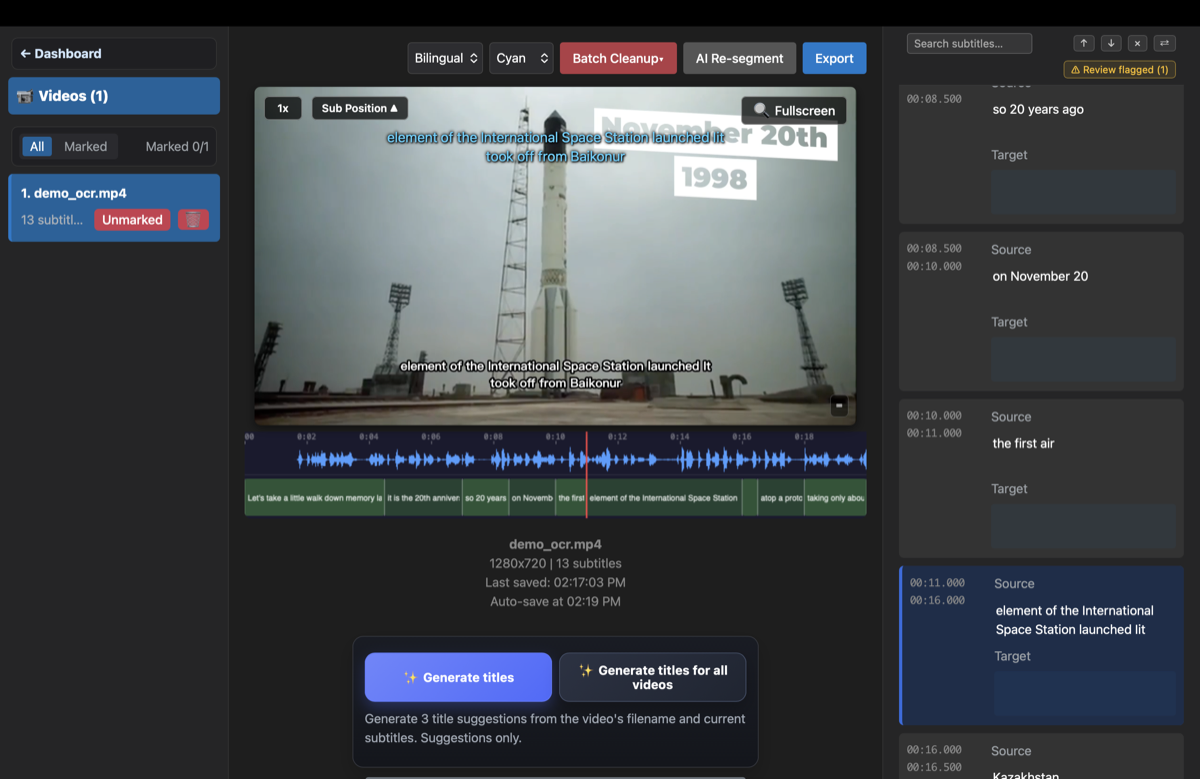
- Ejecuta la extracción con OCR: GeekLink detecta dónde cambia el texto entre fotogramas y crea un archivo de subtítulos con marcas de tiempo, todo en tu Mac.
- Revisa y exporta: corrige cualquier desliz del OCR en el editor integrado (marca las líneas que vale la pena revisar) y luego exporta el SRT, o traduce a otro idioma y quema nuevos subtítulos.
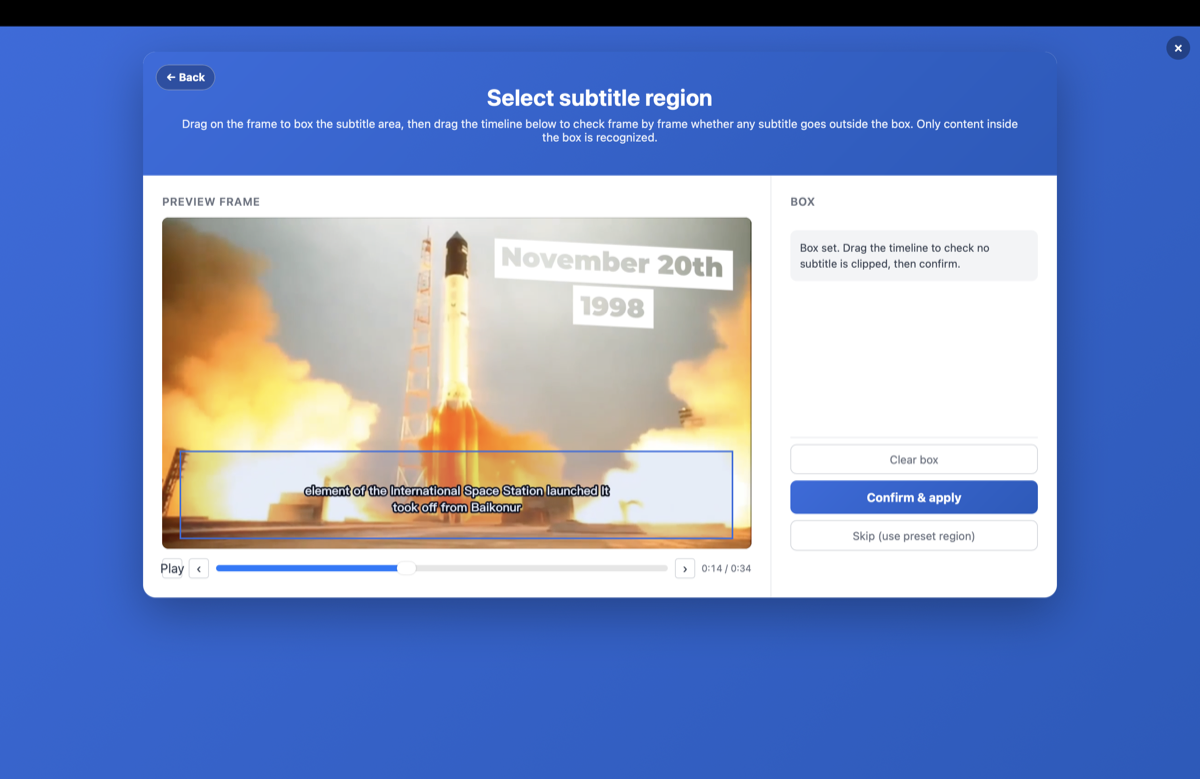
¿Cómo evitas que el OCR capture logos y marcas de agua?
Los clips de noticias, los dramas cortos y las reediciones están llenos de elementos en pantalla: logos de canales, distintivos de "NOTICIAS", gráficos de fondo grandes. Tú solo quieres la línea del subtítulo.
Además de dibujar el recuadro, GeekLink puede filtrar por tamaño y color de fuente, de modo que el OCR conserve solo el texto que parece un subtítulo y descarte todo lo demás. Detecta cada fragmento de texto del fotograma y etiqueta su tamaño; tú pasas el pincel sobre el subtítulo real para tomar una muestra de su color. Entonces el OCR conserva, por ejemplo, la pequeña línea blanca del subtítulo e ignora el logo gigante y la marca de agua.

¿Qué tan preciso es el OCR y cómo obtienes los mejores resultados?
Para subtítulos limpios a 720p o más, el OCR suele alcanzar alrededor del 90–98 % de precisión, y el editor integrado de GeekLink te permite corregir el resto rápidamente marcando solo las líneas de las que no está seguro, así no tienes que volver a leer cada línea.
Para obtener los mejores resultados:
- Usa video de alta resolución (720p o más): más píxeles por carácter significan lecturas más limpias.
- Asegúrate de que los subtítulos tengan buen contraste con el fondo.
- Dibuja el recuadro de la región para que la línea del subtítulo quede aislada de logos, marcas de agua y gráficos en pantalla.
- Para chino / japonés / coreano, GeekLink usa modelos CJK especializados que superan al OCR genérico.
Cuando el texto quemado es demasiado pequeño o borroso pero el audio es claro, el reconocimiento de voz (Whisper) puede ser la mejor opción: GeekLink hace ambas cosas.
¿Por qué usar GeekLink para la extracción con OCR?
- 100 % local: el OCR se ejecuta por completo en tu Mac, sin subir tu video a un servicio en la nube.
- Múltiples sistemas de escritura: chino (simplificado/tradicional), japonés (kanji + kana), coreano (hangul), árabe (RTL) y escrituras latinas.
- Selección de región dibujando un recuadro: extrae solo la línea del subtítulo, no los logos ni las marcas de agua que la rodean.
- Marca las líneas que vale la pena revisar: revisas un pequeño puñado en lugar de leer cada subtítulo.
- Un solo flujo de trabajo: extraer → editar → traducir → quemar, sin cambiar de herramienta.
Preguntas frecuentes
¿Qué son los subtítulos incrustados?
Los subtítulos incrustados (quemados) son texto renderizado de forma permanente en la imagen del video durante la edición. A diferencia de los subtítulos blandos (archivos SRT/ASS), no se pueden desactivar en el reproductor.
¿Puede el OCR extraer subtítulos de cualquier idioma?
El OCR de GeekLink admite chino, japonés, coreano, inglés y la mayoría de los idiomas con escritura latina. También se admiten el árabe y el tailandés con modelos especializados.
¿Qué tan preciso es el OCR frente al reconocimiento de voz?
La precisión del OCR depende de la calidad del video y de la claridad de los subtítulos: normalmente entre el 90 y el 98 % para subtítulos limpios a 720p o más. El reconocimiento de voz (Whisper) es mejor cuando el texto quemado no es claro pero el audio sí lo es.
¿Puedo eliminar los subtítulos incrustados de un video?
GeekLink extrae el texto como un archivo de subtítulos, pero no borra los subtítulos visuales del video. Para "reemplazarlos", superpón nuevos subtítulos traducidos encima.
¿Mi video se sube a algún lugar?
No. El OCR se ejecuta localmente en tu Mac: el video nunca sale de tu dispositivo.
Artículos relacionados
Aviso: GeekLink es nuestro propio producto. Las cifras de precisión del OCR son rangos típicos para subtítulos limpios a 720p o más y varían según la calidad del video.