Resumo: legendas embutidas (queimadas) fazem parte da imagem do vídeo e não podem ser desativadas, então, para recuperar o texto editável, você precisa "ler" as palavras direto da imagem (o nome técnico é OCR). No GeekLink você importa o vídeo, escolhe "Já na tela", desenha uma caixa ao redor da área da legenda e tudo roda localmente no seu Mac — ele lê o texto quadro a quadro e gera um SRT com marcação de tempo que você pode editar, traduzir ou queimar novamente. Download gratuito, funciona totalmente offline e lida com chinês, japonês, coreano, inglês e mais.
Se você pesquisou "extrair legendas embutidas", é porque tem um vídeo em que as legendas fazem parte da imagem — algo comum em curtas-dramas chineses, repostagens de Douyin/Bilibili, rips de DVD e clipes de redes sociais. Veja exatamente como transformar essas legendas queimadas de volta em um arquivo de legenda editável.
O que são legendas embutidas e por que você não consegue desativá-las?
Legendas embutidas — também chamadas de queimadas ou abertas — são textos renderizados permanentemente nos quadros do vídeo durante a edição, de modo que nenhum player consegue escondê-las. Diferente das legendas soft (arquivos SRT/ASS que acompanham o vídeo), não há uma faixa de texto separada para capturar.
Para obter um arquivo editável, você precisa ler o texto direto da imagem com OCR (Reconhecimento Óptico de Caracteres). Esse é o primeiro passo sempre que você quer traduzir um vídeo que só tem legendas queimadas — você não pode traduzir o que ainda não é texto.
Como extrair legendas embutidas, passo a passo?
Todo o fluxo roda localmente no GeekLink — seu vídeo nunca sai do seu Mac.
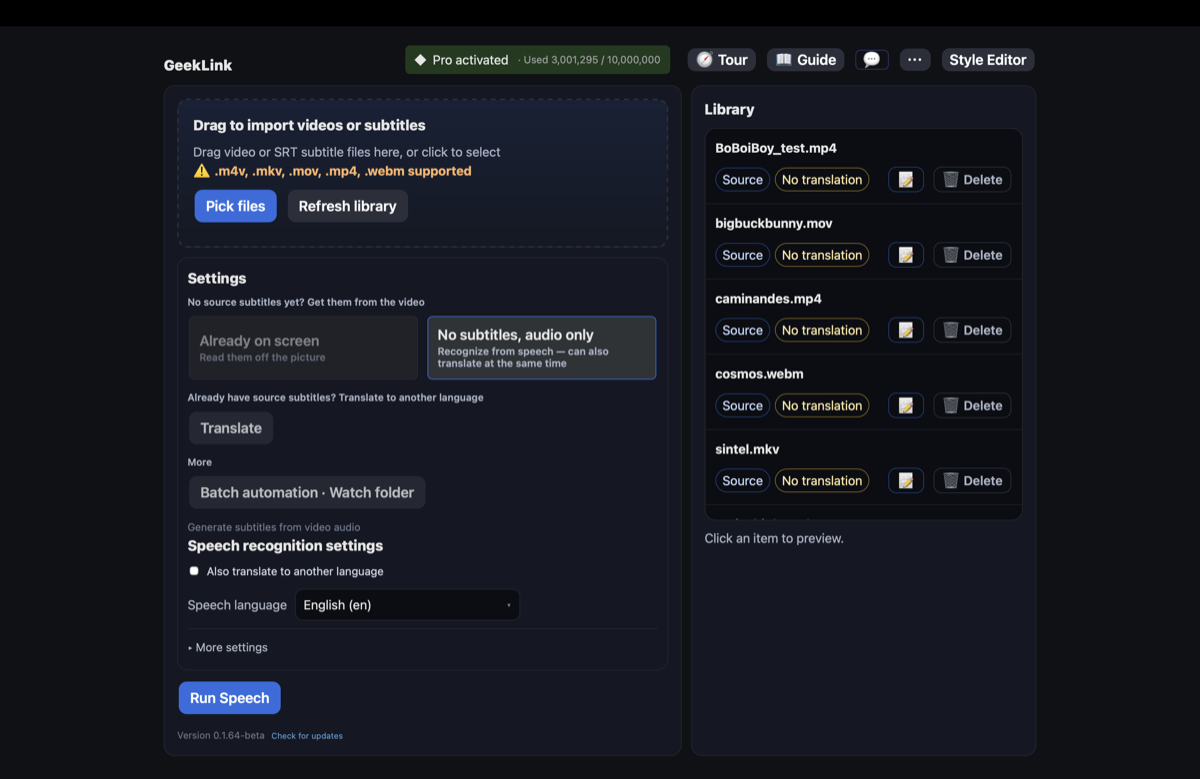
- Importe o vídeo — arraste o vídeo com legendas queimadas (MP4, MOV, MKV e mais).
- Escolha "Já na tela — leia direto da imagem" — essa é a opção para vídeos em que as legendas fazem parte da imagem. (Nos bastidores é OCR, mas você não precisa saber o termo — o botão usa linguagem simples.)
- Desenhe uma caixa ao redor da área da legenda — marque onde ficam as legendas (geralmente no terço inferior). Esse é o passo-chave: ele diz ao OCR para ignorar logos, marcas d'água e outros textos na tela, para que você extraia apenas a linha da legenda.
- Execute a extração com OCR — o GeekLink detecta onde o texto muda entre os quadros e cria um arquivo de legenda com marcação de tempo, tudo no seu Mac.
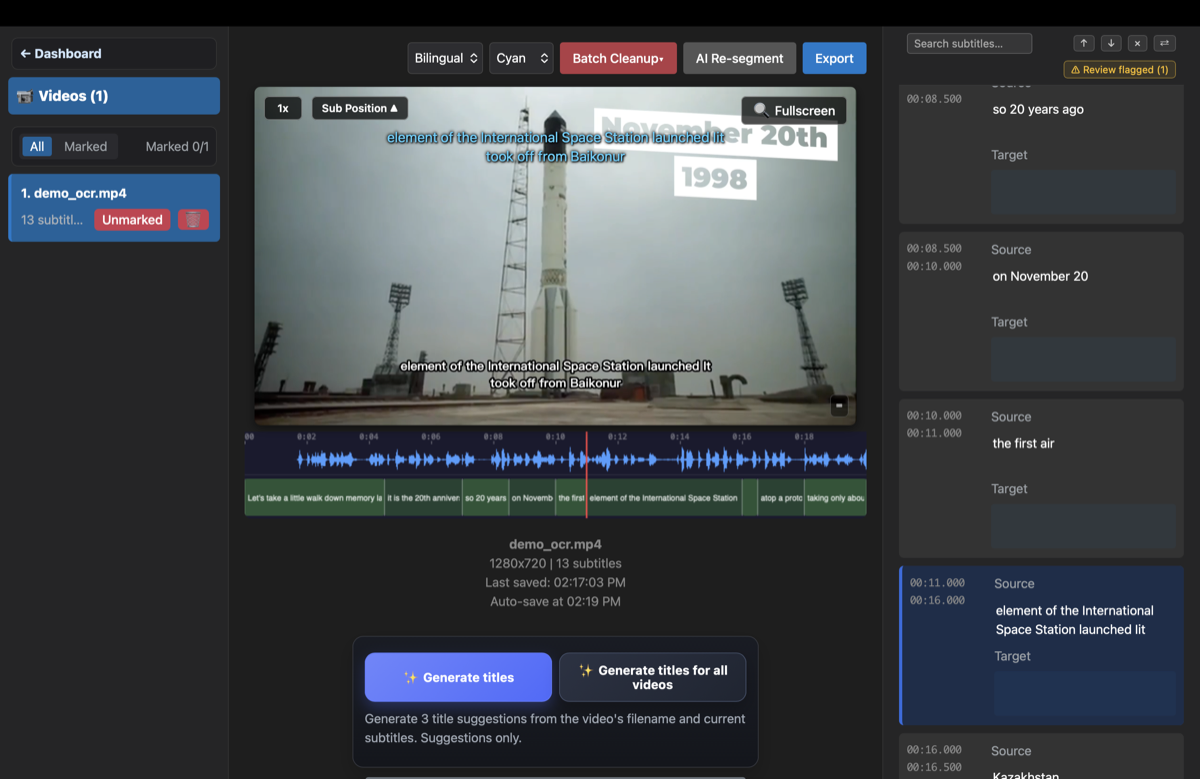
- Revise e exporte — corrija qualquer falha do OCR no editor integrado (ele destaca as linhas que vale a pena conferir), depois exporte em SRT — ou traduza para outro idioma e queime novas legendas.
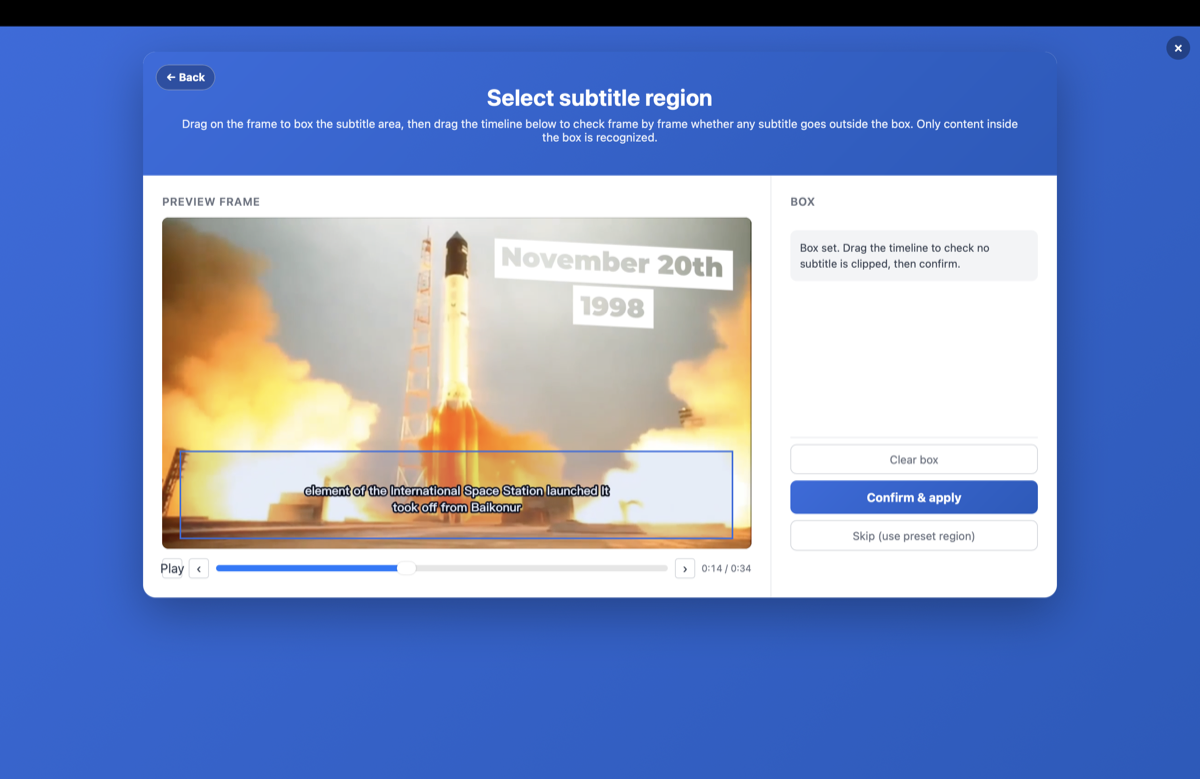
Como evitar que o OCR capture logos e marcas d'água?
Clipes de telejornais, curtas-dramas e repostagens estão cheios de elementos na tela — logos de canais, selos "NEWS", grandes gráficos de fundo. Você só quer a linha da legenda.
Além de desenhar a caixa, o GeekLink pode filtrar por tamanho e cor da fonte — assim o OCR mantém apenas o texto que parece uma legenda e descarta todo o resto. Ele detecta cada trecho de texto no quadro e rotula seu tamanho; você passa o pincel sobre a legenda real para amostrar a cor dela. Então o OCR mantém, por exemplo, a pequena legenda branca e ignora o logo gigante e a marca d'água.

Qual é a precisão do OCR e como obter os melhores resultados?
Para legendas nítidas em 720p ou mais, o OCR costuma atingir cerca de 90–98% de precisão — e o editor integrado do GeekLink permite corrigir o restante rapidamente, destacando apenas as linhas das quais ele não tem certeza, para que você não precise reler cada linha.
Para obter os melhores resultados:
- Use vídeo em alta resolução (720p+) — mais pixels por caractere significam leituras mais limpas.
- Garanta um bom contraste das legendas em relação ao fundo.
- Desenhe a caixa da região para que a linha da legenda fique isolada de logos, marcas d'água e gráficos na tela.
- Para chinês / japonês / coreano, o GeekLink usa modelos CJK especializados que superam o OCR genérico.
Quando o texto queimado é pequeno demais ou está borrado, mas o áudio está limpo, o reconhecimento de fala (Whisper) pode ser o melhor caminho — o GeekLink faz os dois.
Por que usar o GeekLink para extração com OCR?
- 100% local: o OCR roda inteiramente no seu Mac — sem enviar seu vídeo para um serviço na nuvem.
- Vários sistemas de escrita: chinês (simplificado/tradicional), japonês (kanji + kana), coreano (Hangul), árabe (RTL) e escritas latinas.
- Seleção de região desenhando uma caixa: extraia apenas a linha da legenda, não os logos e marcas d'água ao redor.
- Destaca as linhas que vale a pena conferir: você revisa um pequeno punhado em vez de ler cada legenda.
- Um único fluxo: extrair → editar → traduzir → queimar, sem trocar de ferramenta.
Perguntas frequentes
O que são legendas embutidas?
Legendas embutidas (queimadas) são textos renderizados permanentemente na imagem do vídeo durante a edição. Diferente das legendas soft (arquivos SRT/ASS), elas não podem ser desativadas no player.
O OCR consegue extrair legendas de qualquer idioma?
O OCR do GeekLink suporta chinês, japonês, coreano, inglês e a maioria dos idiomas de escrita latina. Árabe e tailandês também são suportados com modelos especializados.
Qual é a precisão do OCR em comparação com o reconhecimento de fala?
A precisão do OCR depende da qualidade do vídeo e da clareza das legendas — normalmente de 90 a 98% para legendas nítidas em 720p+. O reconhecimento de fala (Whisper) é melhor quando o texto queimado está pouco nítido, mas o áudio está limpo.
Posso remover legendas embutidas de um vídeo?
O GeekLink extrai o texto como um arquivo de legenda, mas não apaga as legendas visuais do vídeo. Para "substituí-las", sobreponha novas legendas traduzidas por cima.
Meu vídeo é enviado para algum lugar?
Não. O OCR roda localmente no seu Mac — o vídeo nunca sai do seu dispositivo.
Artigos relacionados
Aviso: o GeekLink é nosso próprio produto. Os números de precisão do OCR são faixas típicas para legendas nítidas em 720p+ e variam conforme a qualidade do vídeo.